[Hyperparameter Optimization] Optuna
안녕하세요. 원래는 지난 포스트에 이어서 Pytorch에 대해 포스팅을 해야 되지만, 이번 포스트에는 조금은 특별하게 제가 가지고 있는 AI 지식 중 하나를 공유드리려고 합니다. 머신러닝 혹은 딥러닝 모델을 만들기 위해서는 초모수라고 불리는 Hyperparameter를 최적화하는 작업이 필요합니다. 그 튜닝 라이브러리 중 하나인 Optuna에 대해 설명드리겠습니다! 😀 내용을 정리하느라고 지난 주에 포스팅을 못했었네요.
정의
머신러닝 혹은 딥러닝 모형을 생성할 때, 가장 최적의 성능을 낼 수 있는 초모수(Hyperparameter)를 찾아야 합니다. 초모수를 찾는 방법은 여러가지가 있으나, 그 동안은 주로 GridSearchCV를 이용하여 모든 경우의 수를 탐색하는 방법을 사용했습니다. 이는 조합의 수가 일정 수준 이상으로 많아질 경우에 시간이 매우 오래 걸린다는 단점이 있었습니다. Optuna 라이브러리는 초모수 튜닝에 사용되는 AutoML 기법으로 초모수의 범위를 직접 지정하여 자동으로 최상의 결과를 내는 초모수를 찾아줍니다. 그리고 파라미터 간의 관계와 모델이 최적화 되는 History를 좋은 시각화를 통해 확인할 수 있습니다. 최적화 기법은 Optuna 이외에도 앞에서 설명했던 GridSearchCV와 Random Search, Bayesian Optimization 등이 있습니다. 이에 대해서는 추후에 정리하여 같이 설명드리겠습니다. 그럼 실제로 예시를 통해 확인해보죠!
특징
머신러닝 기법 중 Boosting 기법인 CatBoost를 이용하여 분류 모델을 만들려고 합니다. 여기서 데이터는 Kaggle에서 구한 데이터로 <Pima Indians Diabetes Database> 를 사용했습니다. 최소 21세 이상의 피마 인디언 여성들에 대한 의료 데이터로 Y 변수는 당뇨병 진단 여부를 의미합니다. 분석은 Colab에서 진행했습니다.
우선 Optuna와 Catboost는 Colab에 내장되어 있는 라이브러리가 아니므로 따로 설치를 해야합니다. 설치 후에 아래와 같이 import를 진행합니다.
!pip install optuna
!pip install catboost
from catboost import CatBoostClassifier
import optuna
from optuna import Trial
from optuna.samplers import TPESampler
import time
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import roc_auc_score
간단하게 전처리 한 데이터는 다음과 같습니다. 파일 경로는 ~기호로 생략합니다! ㅎㅎ
pima = pd.read_csv('/~/diabetes.csv')
pima.columns = ['INDEX', 'Preg', 'Glu', 'Blood', 'Skin', 'Insul', 'BMI', 'Fam', 'Age', 'Outcome']
pima = pima.loc[(pima['Glu'] > 0) & (pima['Blood'] > 0) & (pima['Skin'] > 0) & (pima['Insul'] > 0) & (pima['BMI'] > 0), :]
pima = pima.drop('INDEX', axis = 1)
pima.reset_index(drop = True, inplace = True)
X = pima.drop('Outcome', axis = 1)
y = pima.loc[:, 'Outcome' : 'Outcome']
print(X.shape)
print(y.shape)
--------------------------------------------------------------------------------------------------------------------------------
(392, 8)
(392, 1)
데이터를 train 데이터와 test 데이터로 분할합니다. 결측치 값 확인을 위해 info 함수를 이용했고, 모두 값이 존재하는 것을 확인했습니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 39, stratify = y)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
X_train.info()
--------------------------------------------------------------------------------------------------------------------------------
(274, 8)
(118, 8)
(274, 1)
(118, 1)
<class 'pandas.core.frame.DataFrame'>
Int64Index: 274 entries, 140 to 329
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Preg 274 non-null int64
1 Glu 274 non-null int64
2 Blood 274 non-null int64
3 Skin 274 non-null int64
4 Insul 274 non-null int64
5 BMI 274 non-null float64
6 Fam 274 non-null float64
7 Age 274 non-null int64
dtypes: float64(2), int64(6)
memory usage: 19.3 KB
그리고 Hyperparameter Optimization을 위해 train 데이터를 part train 데이터와 validation 데이터로 다시 분할합니다.
X_partrain, X_val, y_partrain, y_val = train_test_split(X_train, y_train, test_size = 0.3, random_state = 39, stratify = y_train)
print(X_partrain.shape)
print(X_val.shape)
print(y_partrain.shape)
print(y_val.shape)
--------------------------------------------------------------------------------------------------------------------------------
(191, 8)
(83, 8)
(191, 1)
(83, 1)
이제 Optuna 라이브러리를 이용해봅시다! Optuna는 초모수의 범위를 사용자가 직접 정할 수 있고, 그 안에서 최적 성능의 초모수를 찾아줍니다. 아래 각각의 함수들은 어떤 형태의 값들을 범위 내에서 Random하게 탐색할지를 정해줍니다.
- optuna.trial.Trial.suggest_categorical() : List 내에서 값을 선택
- optuna.trial.Trial.suggest_int() : 범위 내에서 정수값을 선택
- optuna.trial.Trial.suggest_float() : 범위 내에서 실수값을 선택
- optuna.trial.Trial.suggest_uniform() : 범위 내에서 균일분포 값을 선택
- optuna.trial.Trial.suggest_discrete_uniform() : 범위 내에서 이산 균일분포 값을 선택
- optuna.trial.Trial.suggest_loguniform() : 범위 내에서 로그함수 값을 선택
우선 objective 함수를 따로 생성할 것이고, 그 안에 초모수 탐색 범위를 정해줍니다. 아래의 경우는 학습률은 로그함수 값을, 초모수에서 중요한 부분을 차지하고 있는 n_estimators와 max_depth는 정수값으로 탐색합니다. 그 다음 CatBoost 분류 모델을 만듭니다. part train 데이터로 학습하여 validation 데이터 값을 넣었을 때, AUC 점수가 가장 좋은 초모수 값을 채택하고, 100번 이상 초모수가 업데이트가 안될 시 종료하는 프로세스를 아래와 같이 만들었습니다.
def objective(trial : Trial) -> float :
params_cat = {
"random_state" : 39,
'learning_rate' : trial.suggest_loguniform('learning_rate', 0.001, 0.1),
"n_estimators" : trial.suggest_int("n_estimators", 100, 1000),
"max_depth" : trial.suggest_int("max_depth", 3, 8)
}
model = CatBoostClassifier(**params_cat)
model.fit(X_partrain, y_partrain, eval_set = [(X_val, y_val)],
early_stopping_rounds = 100, verbose = False)
cat_pred = model.predict(X_val)
AUC = roc_auc_score(y_val, cat_pred)
return AUC
Optuna가 얼마나 빨리 초모수 최적화 작업을 해주는지 측정하기 위해 time 라이브러리를 이용하여 시간을 측정해보겠습니다. 아래 코드에서 start와 end가 그것입니다. Optuna는 앞서 말씀드렸듯이, 모든 경우의 수에 대해 성능을 계산하지 않습니다. 즉, 사용자가 지정한 범위 내의 초모수를 Sampling 하여 성능을 비교합니다. 즉, 범위를 잘 지정하는 것도 중요하지만, Sampling을 어떻게 하느냐에 따라 결과도 크게 달라집니다. 저는 TPESampler를 이용했습니다. Sampler에 대한 내용은 저도 추가적으로 공부한 뒤에 포스팅하도록 하겠습니다. 공부할 것들이 많네요… 🤣 성능 지표가 AUC 이므로 direction을 “maximize”로 하여 AUC 값이 큰 쪽으로 초모수를 선택하도록 했고, 총 100번의 시뮬레이션을 했습니다.
start = time.time()
sampler = TPESampler(seed = 39)
study = optuna.create_study(
study_name = "cat_parameter_opt",
direction = "maximize",
sampler = sampler)
study.optimize(objective, n_trials = 100)
end = time.time()
--------------------------------------------------------------------------------------------------------------------------------
[I 2023-08-20 09:46:02,765] A new study created in memory with name: cat_parameter_opt
[I 2023-08-20 09:46:04,004] Trial 0 finished with value: 0.6866883116883117 and parameters: {'learning_rate': 0.012410186619312995, 'n_estimators': 818, 'max_depth': 7}. Best is trial 0 with value: 0.6866883116883117.
[I 2023-08-20 09:46:05,846] Trial 1 finished with value: 0.6957792207792207 and parameters: {'learning_rate': 0.0017542833184007157, 'n_estimators': 642, 'max_depth': 6}. Best is trial 1 with value: 0.6957792207792207.
[I 2023-08-20 09:46:06,414] Trial 2 finished with value: 0.70487012987013 and parameters: {'learning_rate': 0.008468701231876565, 'n_estimators': 524, 'max_depth': 6}. Best is trial 2 with value: 0.70487012987013.
......
Optuna의 최적화 소요시간은 약 39.3초로 굉장히 빨리 나온 것을 볼 수 있네요!
print(f"{end - start:.5f} sec")
--------------------------------------------------------------------------------------------------------------------------------
39.27664 sec
아래 코드와 같이 가장 좋은 성능의 모델일 때의 초모수를 도출할 수 있습니다. 성능은 AUC 71.4%가 나왔고, 학습률 0.002, 나무 개수 574개, 가지 깊이 4일 때의 모델이 가장 좋았다고 말해주고 있네요.
print("Best Score :", study.best_value)
print("Best trial :", study.best_trial.params)
--------------------------------------------------------------------------------------------------------------------------------
Best Score : 0.713961038961039
Best trial : {'learning_rate': 0.002062014141105374, 'n_estimators': 574, 'max_depth': 4}
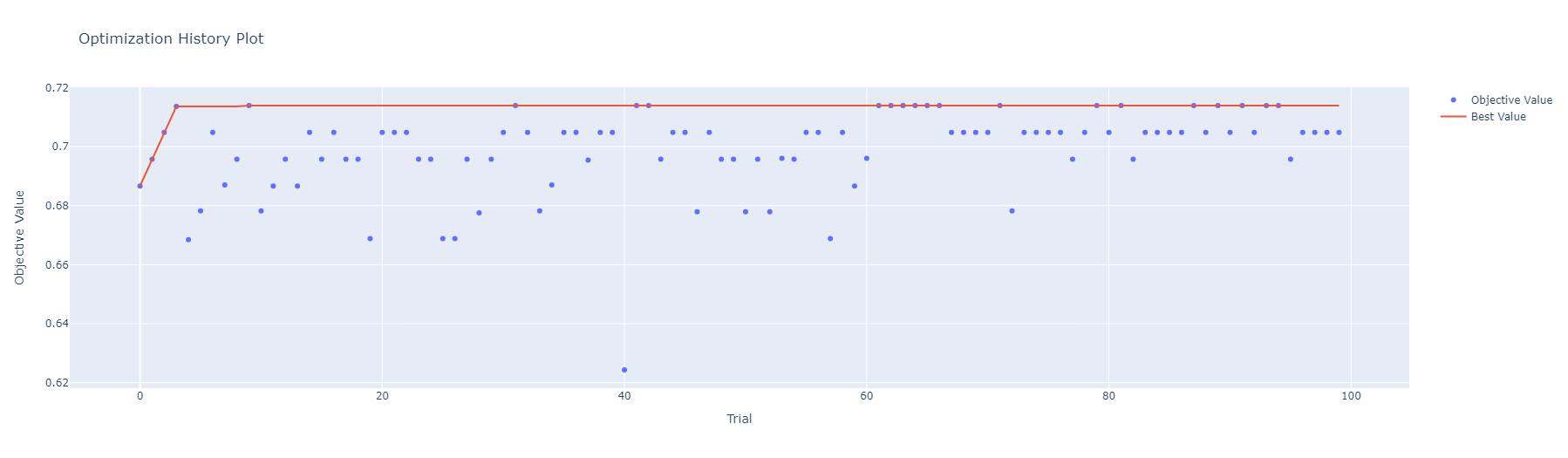
Optuna에 내장되어 있는 시각화 함수도 한번 알아봅시다! plot_optimization_history를 이용하면 최적화가 어떻게 이루어졌는지 기록이 시각화되어 도출됩니다. 결과로 보았을 땐, Trial 3일 때가 가장 좋은 것으로 보였는데 제가 보여드리지는 않았지만 [Best is trial 9 with value] 결과가 도출된 것으로 봐서는 Trial 9가 가장 좋았다는 것을 알 수 있네요! 아래의 그림을 보았을 때, 빨간 줄에 Objective Value 값이 후반부에도 다소 분포하는 것을 볼 수 있습니다. 따라서 저라면 100보다 더 큰 Trial 수를 지정하여 한번 더 최적화를 진행해볼 것 같습니다. 이렇듯 적절한 Trial 개수를 시각화를 통해 정해볼 수 있습니다.
optuna.visualization.plot_optimization_history(study)
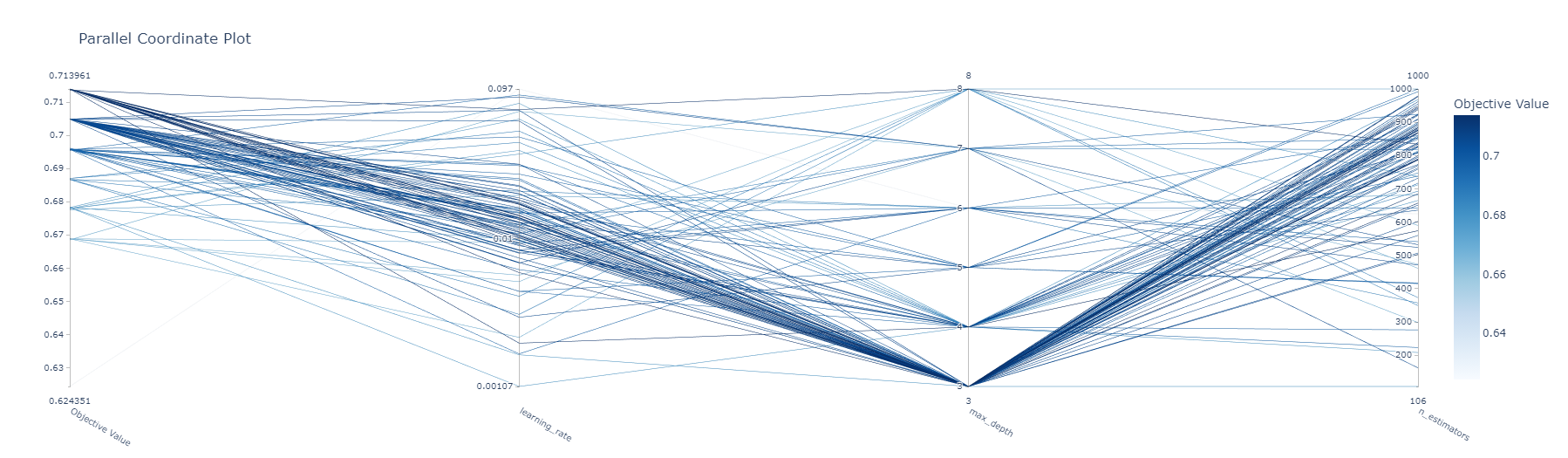
다음으로 plot_parallel_coordinates입니다. 파라미터 간의 관계를 확인할 때 유용하게 사용됩니다. 아래 결과를 보다시피 각 변수당 100개의 점들이 부분마다 찍혀있고, 이를 직선으로 연결한 그래프를 볼 수 있습니다. 이를 통해 max_depth의 수가 적을수록 n_estimators는 커지려 하는 경향성을 볼 수 있습니다. 가지 수가 적어지니 나무 수가 증가해야 함은 어떻게 보면 당연하게 생각됩니다. 저의 경우 초모수 탐색 범위를 지정할 때도 이 결과를 많이 참고합니다. 만약 max_depth가 3이 아닌 8에 훨씬 점들이 많이 찍혀있고, 직선도 많이 연결되어 있다면 범위를 [3, 8]이 아닌 [3, 10] 정도로 늘려보는 편입니다.
optuna.visualization.plot_parallel_coordinate(study)
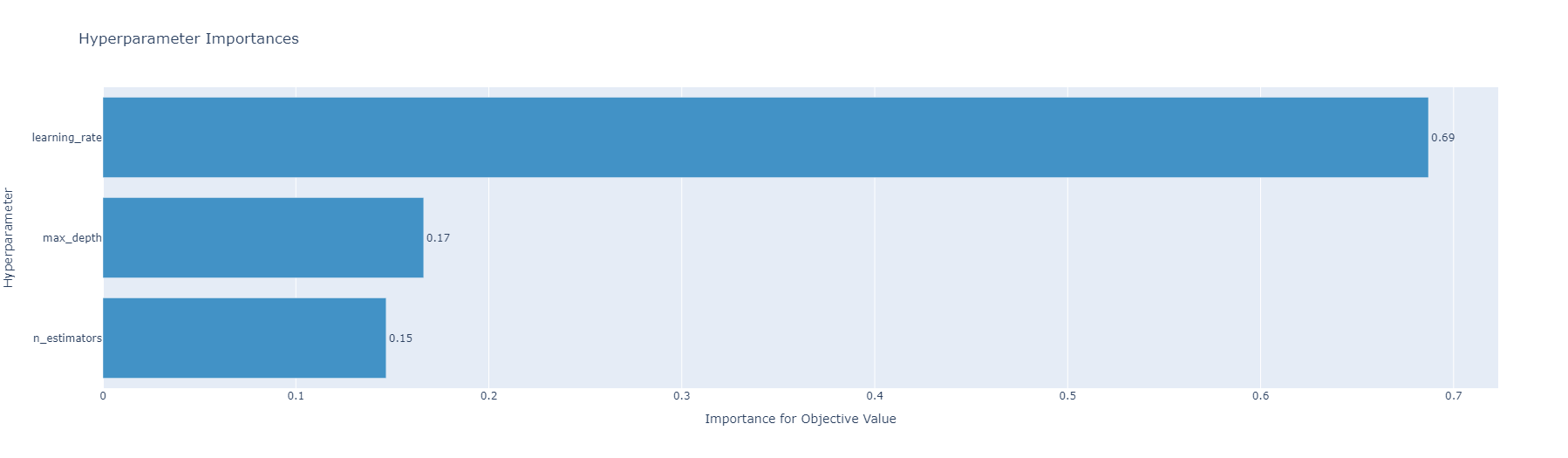
plot_param_importances는 초모수의 중요도를 시각화 해주는 함수입니다. 이 데이터에서는 학습률이 가장 중요하다고 하는 군요! 이전에 plot_parallel_coordinates 결과를 보면 학습률의 점들이 다른 초모수보다 넓게 분포하고 있는 것을 볼 수 있습니다. 이를 다시 생각해보면, 다른 초모수보다 학습률 값을 잘 조정해주고 신경을 써줘야 한다는 것을 의미합니다.
optuna.visualization.plot_param_importances(study)
 마지막으로 plot_slice입니다. 각 초모수에 대하여 개별적인 최적의 부분 공간이 어디에 위치하는지 이해하는 데 도움을 준다고 합니다. 개인적으로 크게 사용하는 시각화는 아닙니다.
마지막으로 plot_slice입니다. 각 초모수에 대하여 개별적인 최적의 부분 공간이 어디에 위치하는지 이해하는 데 도움을 준다고 합니다. 개인적으로 크게 사용하는 시각화는 아닙니다.
optuna.visualization.plot_slice(study)
자 그럼 이제 한번 비교를 해봅시다! 아래는 GridSearchCV를 통해 초모수 최적화를 한 결과입니다. GridSearchCV는 사용자가 초모수의 범위가 아닌 초모수 각각의 원하는 값을 지정하면, 그에 대한 모든 경우의 수를 계산하여 최적의 초모수를 도출합니다. 아래의 경우의 수를 모두 계산한다면 $5 \times 5 \times 5 = 125$가 됩니다. 3개의 초모수에 대해 각각 5개의 값만 사용자가 지정을 했으므로, 뭔가? 범위로 지정을 한 Optuna 보다는 훨씬 빠른 시간 내에 결과가 도출될 것 같습니다!
start = time.time()
param_grid = [{
'learning_rate' : [0.02, 0.04, 0.06, 0.08, 0.1],
"n_estimators" : [100, 200, 300, 400, 500],
"max_depth" : [3, 4, 5, 6, 7]}]
gs = GridSearchCV(estimator = CatBoostClassifier(random_state = 39, verbose = False), param_grid = param_grid, scoring = 'roc_auc')
model = gs.fit(X_partrain, y_partrain)
print(model.best_score_)
print(model.best_params_)
end = time.time()
--------------------------------------------------------------------------------------------------------------------------------
0.8393826429980276
{'learning_rate': 0.02, 'max_depth': 3, 'n_estimators': 400}
하지만 시간은 219초로 39초의 Optuna보다 소요시간이 훨씬 걸린다는 것을 알 수 있습니다. 게다가 Optuna는 GridSearchCV와 달리 범위 내의 Sampling 된 값들에 대해 초모수 최적화를 해주므로 보다 정확한 초모수 값을 계산해줍니다.
print(f"{end - start:.5f} sec")
--------------------------------------------------------------------------------------------------------------------------------
219.06270 sec
Reference

댓글남기기