[Modeling] ExtraTrees
이번 시간에는 Boosting의 기법 중 하나인 ExtraTrees에 대해서 알아보도록 하겠습니다. RandomForest와 비슷한 기법이지만 차이점이 분명히 있는데요. 어떠한 점에서 다르고, 장점이 무엇인지 알아보도록 하겠습니다. 참고로 RandomForest에 대해 사전 지식이 있다면 더욱 이해하기 쉽습니다!
개요
1. Bagging
앞서 ExtraTrees를 이해하기 위해서는 RandomForest가 어떤 것인지 알아야 한다고 설명드렸습니다. 그렇다면 RandomForest를 이해하기 위해 우선 Bagging에 대해서 알아보도록 하죠! 성능 좋은 머신러닝 모델을 만들기 위해서는 당연하게도 학습 데이터 수가 많아야 합니다. 학습데이터를 늘리는 방법은 여러가지가 있는데 그 중 하나의 방법이 바로 Bagging입니다. Bagging은 원래의 학습데이터를 Bootstrap하는 방법입니다. 여기서 Bootstrap이란 쉽게 말씀드리자면 임의로 표본을 복원추출로 뽑는 것을 말합니다. 예를 들어, 원래 데이터가 {“빨강”, “파랑”, “노랑”, “초록”, “보라”}로 구성되어 있을 때, Bootstrap 표본을 만든다면 한 번 뽑힌 표본도 다시 뽑을 수 있게 때문에 새로운 데이터로 {“빨강”, “빨강”, “노랑”, “노랑”, “보라”}와 같은 데이터를 만들 수 있습니다. 이렇듯 붓스트랩을 이용한 새로운 학습 데이터셋을 생성하는 Bagging을 머신러닝에서 주로 사용합니다.
2. RandomForest
그렇다면 왜 RandomForest를 이해하기 위해서 Bagging 내용이 필요할까요? 바로 RandomForest는 TREE 기법의 Bagging 버전이라 할 수 있기 때문입니다. 자세하게 설명하면 내용이 길어지기 때문에 RandomForest에 대해 간단히 분석 절차를 설명드리겠습니다.
-
데이터 shape이 $(n, p)$일 때, $n$개의 Bootstrap 표본을 추출해서 새로운 학습 데이터를 만듭니다.
-
새로 만든 데이터를 TREE 모델에 적용시킵니다.
이 때, TREE의 노드마다 $p$개의 변수 중 Random하게 $k$개의 변수를 뽑아 TREE 모델을 만듭니다.
-
1과 2를 $M$번 반복합니다.
-
만들어진 $M$개의 TREE 예측치를 분류/회귀 모델에 따라 Voting/평균으로 계산하여 최종예측치를 구합니다.
아래 예시를 들어보겠습니다. 주황색과 파랑색 데이터를 분류하는 TREE 모델을 만드려 합니다. 이때, 노드 분할은 두 점들을 최적으로 분리할 수 있는 분할점으로 이루어집니다.
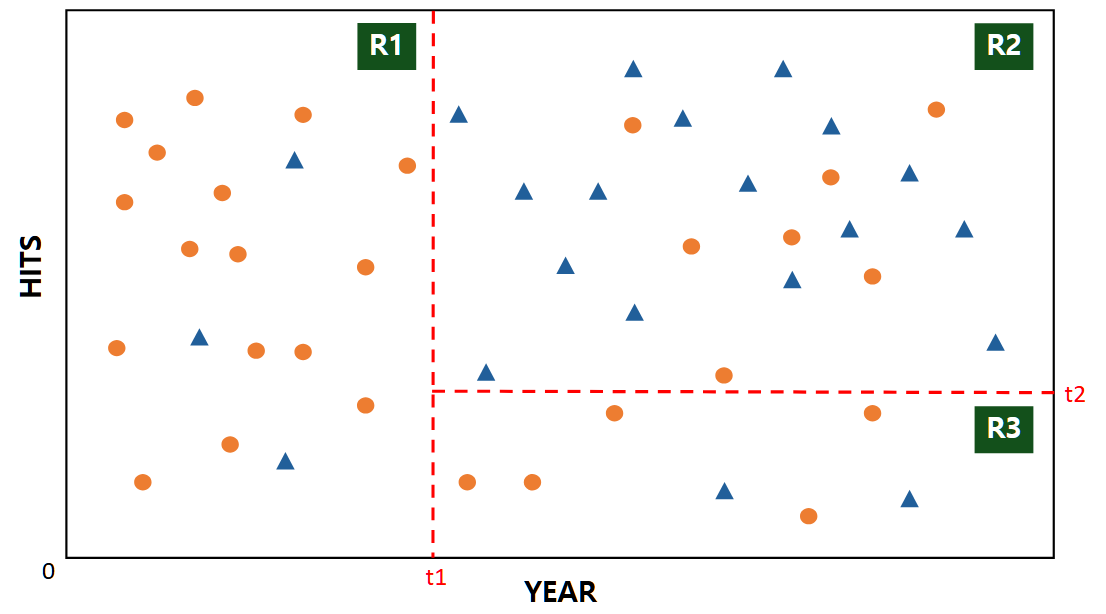
분할점 t1과 t2가 정해진다면 아래와 같은 TREE Logic으로 분할이 이루어집니다. 여기서 R1에 해당되는 영역은 주황점, R2는 파랑점으로 예측하게 됩니다. 이러한 TREE 모델들이 점점 많아져 숲을 이루게 되면 Voting 또는 평균을 이용해 최종예측치를 만들어내어 RandomForest가 완성됩니다.
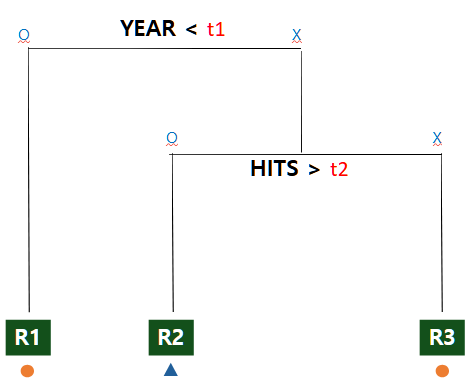
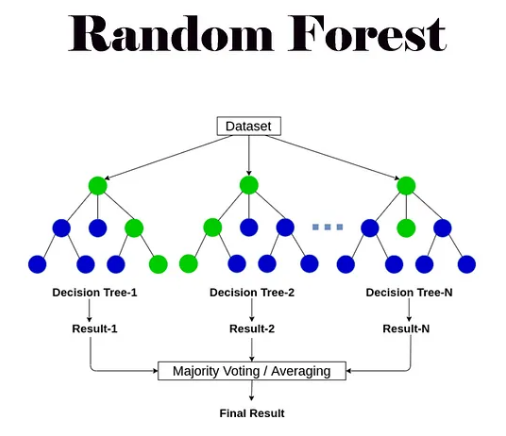
결국, RandomForest 기법 특징에 대해 정리해서 말하자면 아래와 같습니다.
- Bootstrap을 이용한 Bagging 기법으로 새로운 데이터 표본을 생성합니다.
- 노드 분할에서 최적의 분할로 선택합니다.
- 2번의 이유 때문에 연산량이 증가하여 속도가 느립니다.
정의
3. ExtraTrees
ExtraTrees는 Random하게 $k$개의 변수를 뽑아 TREE 모델을 여러 개 만든다는 점에서 RandomForest 기법과 거의 동일합니다. 여기에 극도의 무작위화를 더하여 과대적합을 줄인 머신러닝 기법이라고 할 수 있겠습니다. ExtraTrees는 RandomForest와 비교했을 때, 두 가지의 다른 특징이 있습니다.
-
Bootstrap을 이용하지 않고, 전체 모든 데이터를 이용합니다. 즉, Bagging이 아닙니다.
-
노드 분할에서 최적 분할이 아닌 Random 분할을 이용합니다. 쉽게 말해서, 노드를 나누는 것도 무작위로 분할합니다.
위의 RandomForest 예시를 들자면, t1과 t2가 Random하게 정해진다는 것을 의미합니다.
1번과 같이 모든 데이터를 이용하기 때문에 Bootstrap을 이용한 표본보다는 bias가 낮아질 수도 있으나, 2번에서 Random 분할을 이용하기 때문에 bias가 높아질 수도 있습니다. 다만, 무작위로 분할하기 때문에 variance는 확실히 낮아지고, 과대적합의 가능성을 막아줍니다.
또한, 모든 가능성을 계산해야 하는 최적 분할과 달리, Random 분할이기 때문에 연산량이 적고 속도가 빠르다는 점도 장점이라고 할 수 있습니다.
실습
이번 실습 데이터는 Scikit의 유방암 진단 DataSet을 사용해 보았습니다.
- 데이터 특징
- Shape : $(569, 31)$
먼저 load_breast_cancer()를 이용해 X, y 데이터를 불러옵니다.
import numpy as np
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
from sklearn.model_selection import cross_val_score
import time
data = load_breast_cancer()
X = pd.DataFrame(data["data"], columns = data['feature_names'])
y = data["target"]
print(X.shape)
print(y.shape)
--------------------------------------------------------------------------------------------------------------------------------
(569, 30)
(569,)
RandomForest와 ExtraTrees 각각의 분류 모델 코딩 속도와 성능을 비교해 보도록 하겠습니다. 원래라면 Train Data와 Test Data를 나눠서 검증을 해야 하나, 데이터를 분할하지 않고 간단히 CV를 이용해 확인했습니다.
먼저 RandomForest입니다. 교차검증 했을 때, 성능은 95.96%이며, 속도는 2.57초로 기록되었습니다.
start_time = time.time()
rf = RandomForestClassifier(random_state = 39)
cv_score = cross_val_score(rf, X, y, cv = 5).mean()
print("Average Cross Validation Score Of RandomForest is ", cv_score)
print("--- %s seconds ---" % (time.time() - start_time))
--------------------------------------------------------------------------------------------------------------------------------
Average Cross Validation Score Of RandomForest is 0.95960254618848
--- 2.573277235031128 seconds ---
다음은 ExtraTrees입니다. 교차검증 시, 성능은 96.49%이며, 속도는 0.69초로 기록되었습니다.
start_time = time.time()
etc = ExtraTreesClassifier(random_state = 39)
cv_score = cross_val_score(etc, X, y, cv = 5).mean()
print("Average Cross Validation Score Of ExtraTrees is ", cv_score)
print("--- %s seconds ---" % (time.time() - start_time))
--------------------------------------------------------------------------------------------------------------------------------
Average Cross Validation Score Of ExtraTrees is 0.9648657040832168
--- 0.6850132942199707 seconds ---
결론적으로, ExtraTrees의 처리 속도가 RandomForest 보다 빠른 것으로 확인되었습니다. 물론 성능은 데이터에 따라 달라질 수 있기 때문에 어느 것이 더 좋다고 판단하기는 어렵습니다. 일반적으로 RandomForest가 더 선호되나, 제 경험적으로는 ExtraTrees도 RandomForest 뿐만 아니라 다른 Boosting 기법과 비교했을 때도 좋은 성능을 내는 ML 기법입니다.
Reference
- Medium
- 파이썬을 이용한 통계적 머신러닝 [박유성 지음]
- woodangtang.log
- QuantDare
- woozins.log
- 성지우의 블로그

댓글남기기