[Modeling] Stacking & Blending Ensemble
안녕하세요. 자격증 준비와 공모전 참여로 그 동안 블로그 활동을 조금 뜸했네요… 😁 오늘 전달해드릴 내용은 AI 공모전에서 많이 사용되는 기법 중 하나인 Stacking & Blending Ensemble에 대해 설명드리려 합니다. 공모전에서 상위권에 랭크되어 있는 대부분의 사람들이 정확도를 극한으로 끌어올리기 위해 이 기법들을 사용합니다. 언뜻 보면 두 기법은 비슷해 보이지만 다른 점이 존재합니다. 어떻게 다른지 같이 확인해 보시죠~!
개요
우선 Ensemble 기법이 무엇인지 설명드리겠습니다. Ensemble이란 다양한 ML, DL 기법들을 결합하여 예측성능을 높이는 학습을 말합니다. 데이터 분석을 하게 되면 저마다의 모델링마다 알고리즘, 예측 결과, 성능이 다 다릅니다. 하나의 모델을 사용하는 것보단 많은 모델을 사용하여 결합하는 것이 훨씬 성능이 좋은 모델을 만들 것입니다. 이에 Ensemble 기법은 데이터 분석의 꽃이라고 말할 수 있습니다.
Stacking Ensemble
Stacking Ensemble은 각각의 다양한 모델을 통해 추출된 예측값들을 다시 Train Data와 Test Data로 결합하여 모델링 함으로써 최종 예측을 더 나은 성능으로 만드는 강력한 Ensemble 기법 중 하나입니다. 즉, 서로 다른 모델링을 통해 각각의 예측값을 추출하는 $Stage~1$과 이러한 예측값들을 모아 다시 하나의 Dataset으로 만들어 모델링을 하는 $Stage~2$로 진행하게 됩니다. 자세한 알고리즘 프로세스는 글로만 쓰기에는 꽤 복잡하기 때문에 간단한 예시를 통해 설명드리겠습니다!
아래와 같이 Train Data와 Test Data가 있습니다. Shape는 다음과 같을 것입니다.
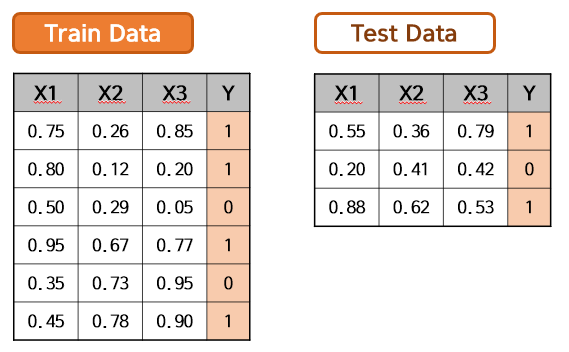
- X_train.shape : $(6, 3)$
- y_train.shape : $(6, )$
- X_test.shape : $(3, 3)$
- y_test.shape : $(3, )$
편의상 $Y$가 $0$ 또는 $1$인 이진분류 모델링으로 가정하겠습니다. 여기서 저는 Model을 하나만 쓰지 않고, Model1 ~ Model4 까지의 4개의 모델을 사용하고 싶습니다. 먼저 Model 1을 사용하여 아래와 같이 Train_pred1과 Test_pred1을 도출했습니다.
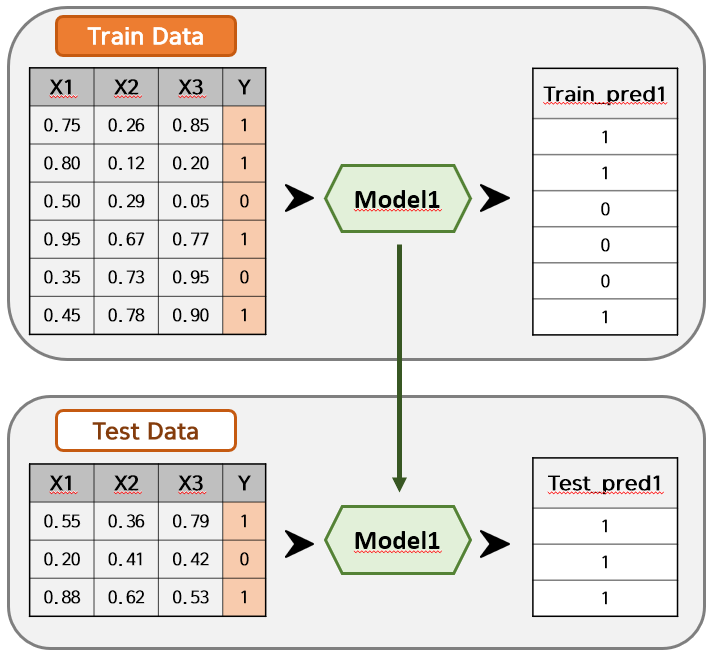
같은 방법으로 Model2~4까지 모델링을 하게 되면 Train_pred2~4와 Test_pred2~4가 생성될 것입니다. 여기서 Stacking을 시도합니다.
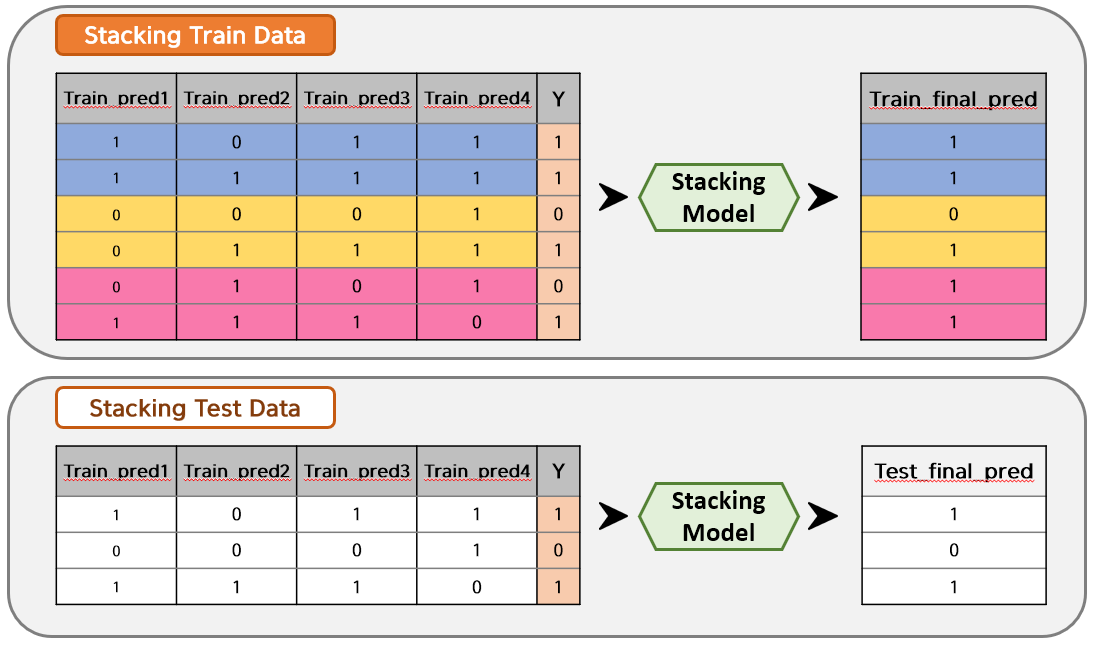
Train Data를 Model1~4에 넣어 추출된 Train_pred1~4 값들을 새로운 Train Data Set으로 결합하고, Test Data를 Model1~4에 넣어 추출된 Test_pred1~4 값들을 새로운 Test Data Set으로 결합합니다. (편의상 각각 Stacking Train Data, Stacking Test Data라고 부르겠습니다.)
그리고 Stacking한 데이터들을 원하는 Model로 학습을 하면 최종 예측값이 추출되는 것입니다.
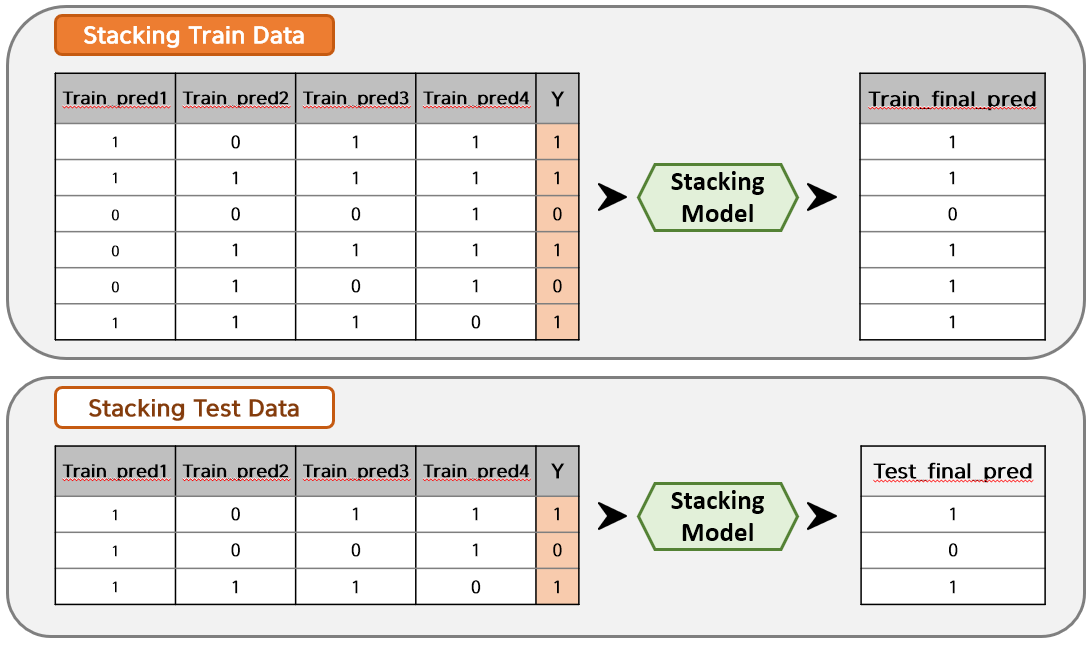
일반적인 Stacking Ensemble 알고리즘은 이와 같으나, 대부분 사람들은 이 방식의 Stacking Ensemble은 사용하지 않습니다. 왜냐하면 Train Data에 과대적합된 모델이 나올 가능성이 매우 크기 때문입니다. 이를 해결하기 위해 CV 기반의 Stacking Ensemble이 나오게 되었습니다. (저도 CV를 사용하는 알고리즘으로 많이 활용하고 있습니다!)
CV 기반의 Stacking Ensemble
CV란 Cross Validation을 말합니다. 즉, KFold 교차검증을 통해 Train Data를 나누고, 각 Fold마다 추출된 Train_pred와 Test_pred를 통해 Stacking하는 기법입니다. 말보다는 예시가 더 이해하기 쉽겠죠?!
아래 예시를 보면 Train Data가 3 Fold로 나뉘어져 있습니다. 이 상태에서 Fold 1~2를 Model 1에 대해 모델링 학습하여 Fold 3를 예측해보겠습니다. 예측한 값은 Train_pred1에 넣습니다. 즉, Fold 3에 해당되는 부분만 Train_pred1에 채워질 것입니다. 그리고 학습한 모델에 Test Data를 입력하여 예측한 값을 pred1_1로 두겠습니다.
마찬가지로 Fold 1, Fold 3를 Model 1에 넣어 학습하고, 학습한 모델에 Fold 2를 입력값으로 넣으면 Train_pred2 예측값이 나올 것이며, 학습한 모델에 Test Data를 입력하면 pred1_2가 나올 것입니다.
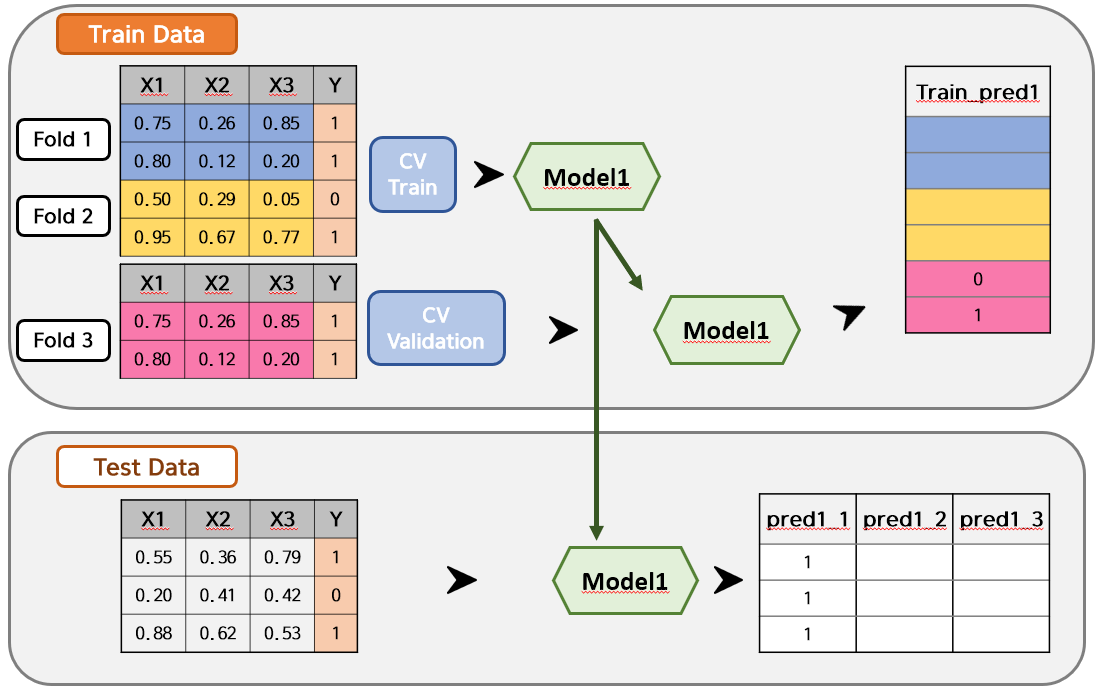
이렇게 모든 Train Data의 Fold에 대해 Model 1을 각각 학습시키면, 아래와 같은 결과가 나옵니다. 그런데 여기서 일반 Stacking Ensemble과 다른 점이 발생합니다. Train_pred1은 하나의 값으로 잘 나왔지만, Test Data의 예측값은 1개가 아닌 Fold의 수인 pred1_1 ~ pred1_3의 3개가 나오게 됩니다. 따라서, 일반적으로는 평균이나 최빈값을 이용하여 하나의 Test_pred1 값으로 만들어줍니다. 만약 평균을 이용한다면, 아래 Test Data 각 행의 예측값은 (1, 0.3, 0.6)이 될 것이고, 0과 1의 기준치인 Threshold를 0.5로 잡는다면 Test_pred1은 (1, 0, 1)이 되는 것이죠!
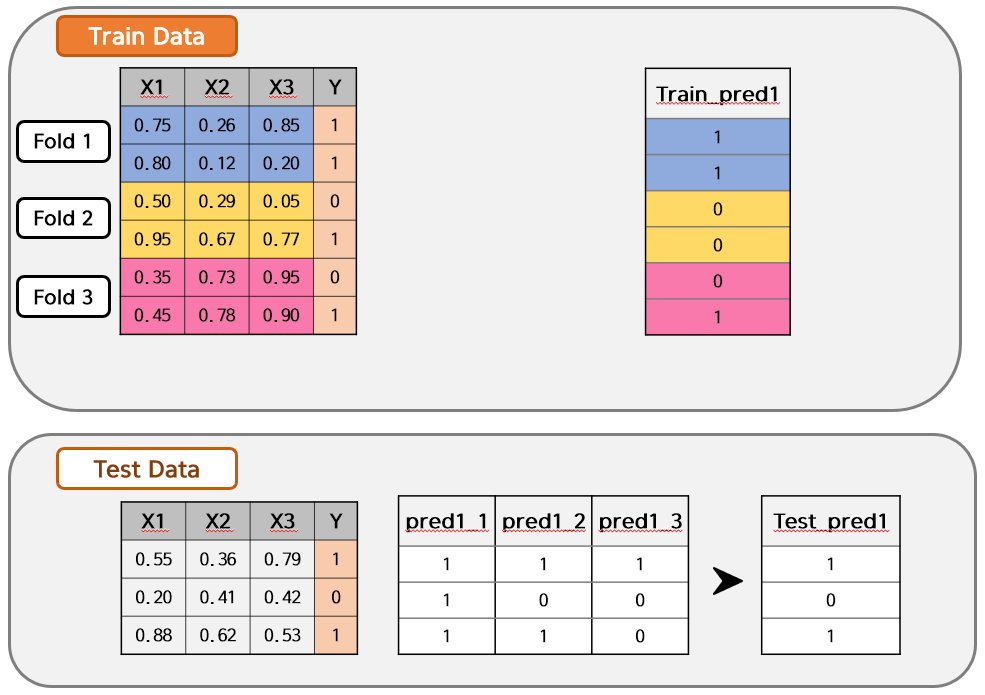
위까지의 과정은 Model 1에 대한 내용입니다. 이를 Model 2~4까지 해주면 아까와 같이 Train_pred1~4와 Test_pred1~4가 만들어지고 Stage 1은 끝나게 됩니다. Stage 2도 KFold 교차검증을 이용한다는 것을 제외하고는 일반 Stacking Ensemble과 동일하게 예측하면 됩니다.
지금까지의 예시는 이진분류를 목적으로 둔 CV 기반의 Stacking Ensemble입니다. 만약, 다중 분류일 경우에는 어떻게 해야 할까요? 다양한 방법이 있겠지만, 저라면 Stage 1에서 predict 값이 아닌 predict_proba 값을 Train_pred와 Test_pred로 가져갈 것 같습니다. 예를 들어 삼진분류의 경우, 각 Model마다 (?, 3)의 Train_predict_proba, Test_predict_proba를 가져갈 것입니다. 즉, 똑같이 Model 1~4를 사용한다고 할 때, Stage 2에서 Stacking Train Data와 Stacking Test Data의 Column 수는 각각 13개가 될 것입니다. (X 변수 12개(4(모델 수) $\times$ 3(Y 범주 수) = 12) + Y 변수 1개)
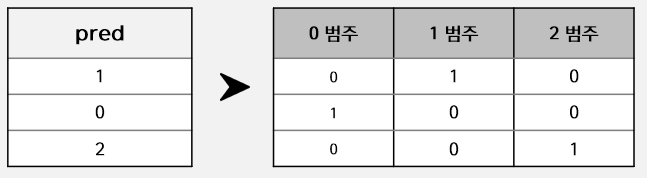
다중 분류에서 predict_proba 값이 아닌 predict 값을 이용해도 상관은 없습니다. 다만, 그대로 가져가면 범주형 값에 대해 평균을 취해야 하니 문제가 될 것이므로, OneHotEncoder 형식과 같이 변환이 필요합니다. 결국, 삼진분류에서 predict 값을 가져가도 Stacking Train Data와 Stacking Test Data의 Column 수는 똑같이 13개가 됩니다.
Y 값이 연속형인 경우는 이러한 문제가 발생하지 않으므로 하나의 열로 가져가면 됩니다! 즉, Model 1~4를 사용한다고 했을 때, Stacking Train Data와 Stacking Test Data의 Column 수는 5개가 됩니다. (X 변수 4개(모델 수 : 4개) + Y 변수 1개)
Blending Ensemble
Blending Ensemble은 KFold 교차검증을 하지 않고, 데이터를 PartTrain-Validation-Test로 나눈 상태에서 각 모델에 대한 Validation의 예측값들을 Validation Data Set에 추가하여 Test Data를 예측하는 방법입니다. 위의 문구에서 PartTrain과 Validation을 합친 것이 Train Data입니다. Stacking Ensemble과 크게 다른 점은 세 가지가 있습니다.
- Stacking Ensemble은 Train Data의 예측값을 Stage 2에 사용하지만, Blending Ensemble은 Validation Data의 예측값을 Stage 2에 사용합니다.
- Stacking Ensemble은 Stage 2에서 예측값만을 이용하지만, Blending Ensemble은 Validation Data의 기존 변수들도 함께 이용합니다.
- Stacking Ensemble은 CV 기반의 교차검증을 이용하는 방법도 있지만, Blending Ensemble은 교차검증을 진행하지 않습니다.
Blending Ensemble도 두 단계에 거쳐서 진행됩니다. Stage 1에서는 서로 다른 모델링을 통해 Validation Data와 Test Data의 예측값을 추출하고 Stage 2에서는 예측값들을 각각 기존 데이터에 변수로서 추가하여 Dataset으로 만들고 모델링을 합니다.
Blending Ensemble은 Stacking Ensemble보다 알고리즘이 간단하여 시간절약에 큰 장점을 가지고 있습니다. 단점은 Stacking Ensemble보다 사용하는 데이터 수가 적어지고, 교차검증을 진행하지 않기 때문에 Validation Data에 과대적합이 될 가능성이 있습니다. 역시 예시를 보도록 하겠습니다.
아래와 같이 Train Data와 Test Data가 있고, Train Data는 PartTrain Data와 Validation Data로 나뉠 것입니다. 각각의 Shape는 다음과 같습니다.
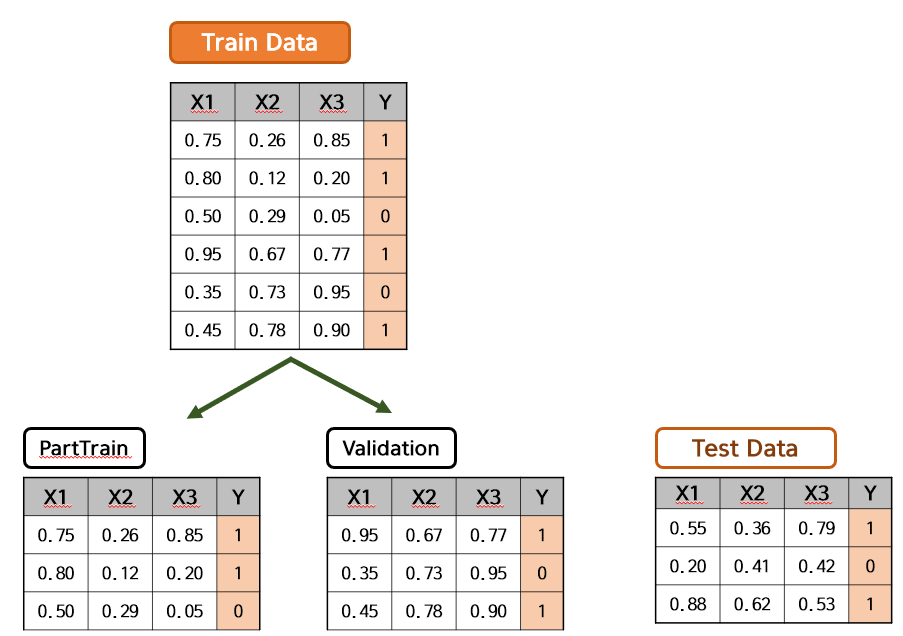
- X_train.shape : $(6, 3)$
- y_train.shape : $(6, )$
- X_partrain.shape : $(3, 3)$
- y_partrain.shape : $(3, )$
- X_val.shape : $(3, 3)$
- y_val.shape : $(3, )$
- X_test.shape : $(3, 3)$
- y_test.shape : $(3, )$
알고리즘은 간단합니다. PartTrain Data로 Model 1을 학습하고 Validation Data와 Test Data를 예측합니다. 예측값은 각각 Val_pred1과 Test_pred1이 도출됩니다.
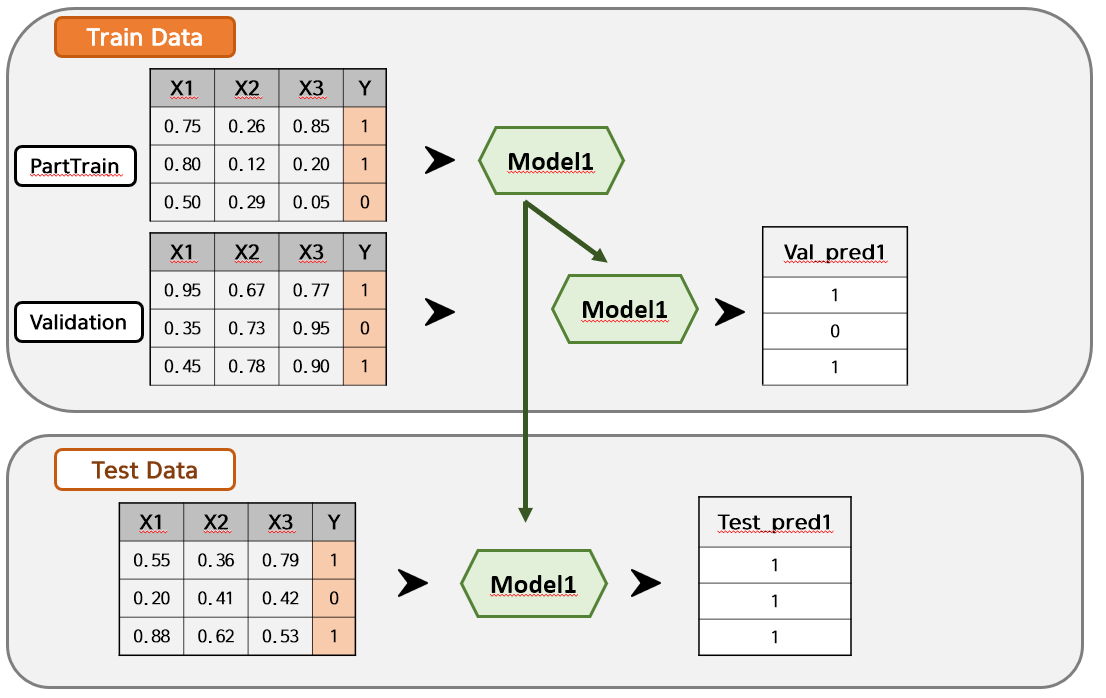
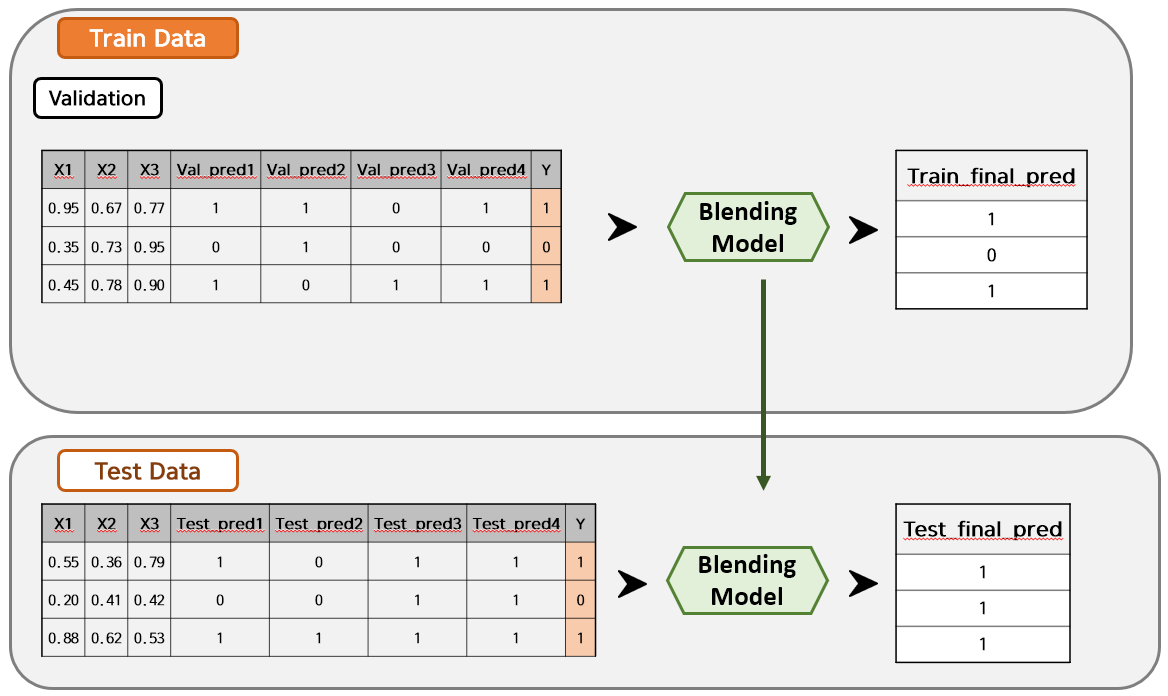
위의 과정을 Model 2~4까지 진행하면 Val_pred2~4와 Test_pred2~4가 만들어집니다. Stage 2에서는 Val_pred1~4와 Test_pred1~4를 각각 Validation Data와 Test Data에 붙입니다. 그리고 원하는 Model로 학습을 하면 최종 예측값이 추출됩니다.
실습
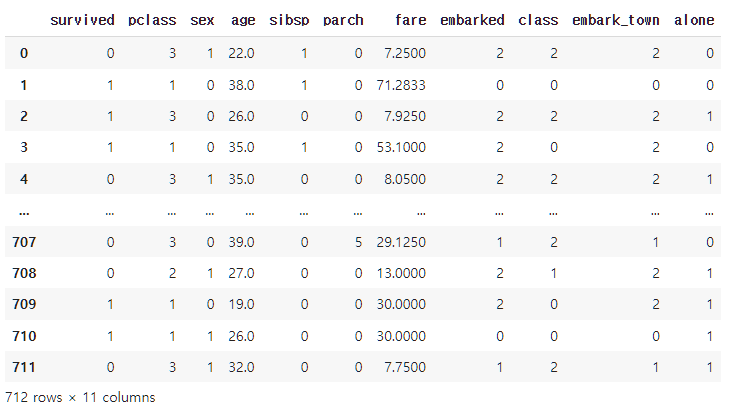
이제 실제 데이터를 이용하여 실습해보죠! 데이터는 Seaborn에서 가져올 수 있는, 어떻게 보면 국민 데이터 중 하나인 타이타닉 데이터를 활용해보겠습니다. 😁 간단히 전처리하여 데이터를 아래와 같이 가져왔습니다.
-
데이터 특징
- Titanic Data : $(712, 11)$
titanic = sns.load_dataset('titanic')
Rdata = titanic.copy()
Rdata2 = Rdata.drop(['deck', 'who', 'adult_male', 'alive'], axis = 1)
Rdata3 = Rdata2.dropna(axis = 0)
Rdata3.reset_index(drop = True, inplace = True)
temp_columns1 = Rdata3.select_dtypes(include = 'object').columns
temp_columns2 = Rdata3.select_dtypes(include = 'bool').columns
temp_columns3 = Rdata3.select_dtypes(include = 'category').columns
le1 = LabelEncoder()
for i in temp_columns1 :
Rdata3[i] = le1.fit_transform(Rdata3[i])
for i in temp_columns2 :
Rdata3[i] = le1.fit_transform(Rdata3[i])
for i in temp_columns3 :
Rdata3[i] = le1.fit_transform(Rdata3[i])
Rdata3
X = Rdata3.drop(['survived'], axis = 1)
y = Rdata3['survived']
print(X.shape)
print(y.shape)
--------------------------------------------------------------------------------------------------------------------------------
(712, 10)
(712,)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 39, stratify = y)
X_train.reset_index(inplace = True, drop = True)
y_train.reset_index(inplace = True, drop = True)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
--------------------------------------------------------------------------------------------------------------------------------
(498, 10)
(214, 10)
(498,)
(214,)
(1) 일반 단일 모델
정확한 비교를 위해 단일 모델로 먼저 성능을 비교해봅시다. 제가 사용하고 싶은 모델은 총 5개로, LightGBM, XgBoost, CatBoost, ExtraTrees, RandomForest입니다. 원래는 초모수도 Optuna를 통해 최적의 Parameter를 구해야 하나 시간상 생략하고 학습했습니다. 각 모델에 대한 Accuracy Score는 다음과 같습니다.
# 1-1. 단일 모델 lightgbm
lgb_model1 = LGBMClassifier(random_state = 39)
lgb_model1.fit(X_train, y_train)
lgb_train_pred1 = lgb_model1.predict(X_train)
lgb_test_pred1 = lgb_model1.predict(X_test)
print(accuracy_score(y_train, lgb_train_pred1))
print(accuracy_score(y_test, lgb_test_pred1))
--------------------------------------------------------------------------------------------------------------------------------
0.9538152610441767
0.7897196261682243
# 1-2. 단일 모델 xgboost
xgb_model1 = XGBClassifier(random_state = 39)
xgb_model1.fit(X_train, y_train)
xgb_train_pred1 = xgb_model1.predict(X_train)
xgb_test_pred1 = xgb_model1.predict(X_test)
print(accuracy_score(y_train, xgb_train_pred1))
print(accuracy_score(y_test, xgb_test_pred1))
--------------------------------------------------------------------------------------------------------------------------------
0.9799196787148594
0.7990654205607477
# 1-3. 단일 모델 catboost
cat_model1 = CatBoostClassifier(random_state = 39, verbose = False)
cat_model1.fit(X_train, y_train)
cat_train_pred1 = cat_model1.predict(X_train)
cat_test_pred1 = cat_model1.predict(X_test)
print(accuracy_score(y_train, cat_train_pred1))
print(accuracy_score(y_test, cat_test_pred1))
--------------------------------------------------------------------------------------------------------------------------------
0.9096385542168675
0.8037383177570093
# 1-4. 단일 모델 extratree
etc_model1 = ExtraTreesClassifier(random_state = 39)
etc_model1.fit(X_train, y_train)
etc_train_pred1 = etc_model1.predict(X_train)
etc_test_pred1 = etc_model1.predict(X_test)
print(accuracy_score(y_train, etc_train_pred1))
print(accuracy_score(y_test, etc_test_pred1))
--------------------------------------------------------------------------------------------------------------------------------
0.9879518072289156
0.780373831775701
# 1-5. 단일 모델 randomforest
rf_model1 = RandomForestClassifier(random_state = 39)
rf_model1.fit(X_train, y_train)
rf_train_pred1 = rf_model1.predict(X_train)
rf_test_pred1 = rf_model1.predict(X_test)
print(accuracy_score(y_train, rf_train_pred1))
print(accuracy_score(y_test, rf_test_pred1))
--------------------------------------------------------------------------------------------------------------------------------
0.9879518072289156
0.8084112149532711
단일 모델에 대한 성능을 보았을 때, 5개 모델 모두 Train Data에 상당히 과대적합된 경향을 볼 수 있습니다. Test Data에 대해 가장 성능이 좋은 모델은 RandomForest 군요!
| Model | Accuracy Score(Train) | Accuracy Score(Test) |
|---|---|---|
| 1. LightGBM | 95.38% | 78.97% |
| 2. XgBoost | 97.99% | 79.91% |
| 3. CatBoost | 90.96% | 80.37% |
| 4. ExtraTrees | 98.80% | 78.04% |
| 5. RandomForest | 98.80% | 80.84% |
(2) CV 기반의 Stacking Ensemble
STAGE 1
참고로 Fold는 7로 두었는데 경험상 이진분류모델에 한하여 5, 7과 같은 홀수가 좋은 것 같습니다. 짝수가 되면 동률이 되어 예측값이 애매해지는 경우가 많기 때문입니다. 이를 피하기 위해 이진분류에서는 Fold를 홀수로 두거나, 아예 predict_proba 값으로 가져가는 것이 좋다고 생각합니다.
다시 돌아와서, 초모수 최적화 작업은 생략하였고 아래와 같이 각 모델에 대한 Train_pred, Test_pred 값을 구합니다.
# 2-1. lightgbm stacking
n_fold = 7
cv = StratifiedKFold(n_splits = n_fold, shuffle = True, random_state = 39)
lgb_train = np.zeros((X_train.shape[0]))
lgb_test = np.zeros((X_test.shape[0]))
print(lgb_train.shape)
for i, (i_trn, i_val) in enumerate(cv.split(X_train, y_train), 1):
print(f'training model for CV #{i}')
lgb_model2 = LGBMClassifier(random_state = 39)
lgb_model2.fit(X_train.loc[i_trn, :], y_train[i_trn])
lgb_train[i_val] = lgb_model2.predict(X_train.loc[i_val, :])
lgb_test += lgb_model2.predict(X_test) / n_fold
# 2-2. xgboost stacking
n_fold = 7
cv = StratifiedKFold(n_splits = n_fold, shuffle = True, random_state = 39)
xgb_train = np.zeros((X_train.shape[0]))
xgb_test = np.zeros((X_test.shape[0]))
print(xgb_train.shape)
for i, (i_trn, i_val) in enumerate(cv.split(X_train, y_train), 1):
print(f'training model for CV #{i}')
xgb_model2 = XGBClassifier(random_state = 39)
xgb_model2.fit(X_train.loc[i_trn, :], y_train[i_trn])
xgb_train[i_val] = xgb_model2.predict(X_train.loc[i_val, :])
xgb_test += xgb_model2.predict(X_test) / n_fold
# 2-3. catboost stacking
n_fold = 7
cv = StratifiedKFold(n_splits = n_fold, shuffle = True, random_state = 39)
cat_train = np.zeros((X_train.shape[0]))
cat_test = np.zeros((X_test.shape[0]))
print(cat_train.shape)
for i, (i_trn, i_val) in enumerate(cv.split(X_train, y_train), 1):
print(f'training model for CV #{i}')
cat_model2 = CatBoostClassifier(random_state = 39, verbose = False)
cat_model2.fit(X_train.loc[i_trn, :], y_train[i_trn])
cat_train[i_val] = cat_model2.predict(X_train.loc[i_val, :])
cat_test += cat_model2.predict(X_test) / n_fold
# 2-4. extratrees stacking
n_fold = 7
cv = StratifiedKFold(n_splits = n_fold, shuffle = True, random_state = 39)
etc_train = np.zeros((X_train.shape[0]))
etc_test = np.zeros((X_test.shape[0]))
print(etc_train.shape)
for i, (i_trn, i_val) in enumerate(cv.split(X_train, y_train), 1):
print(f'training model for CV #{i}')
etc_model2 = ExtraTreesClassifier(random_state = 39, verbose = False)
etc_model2.fit(X_train.loc[i_trn, :], y_train[i_trn])
etc_train[i_val] = etc_model2.predict(X_train.loc[i_val, :])
etc_test += etc_model2.predict(X_test) / n_fold
# 2-5. randomforest stacking
n_fold = 7
cv = StratifiedKFold(n_splits = n_fold, shuffle = True, random_state = 39)
rf_train = np.zeros((X_train.shape[0]))
rf_test = np.zeros((X_test.shape[0]))
print(rf_train.shape)
for i, (i_trn, i_val) in enumerate(cv.split(X_train, y_train), 1):
print(f'training model for CV #{i}')
rf_model2 = RandomForestClassifier(random_state = 39, verbose = False)
rf_model2.fit(X_train.loc[i_trn, :], y_train[i_trn])
rf_train[i_val] = rf_model2.predict(X_train.loc[i_val, :])
rf_test += rf_model2.predict(X_test) / n_fold
STAGE 2
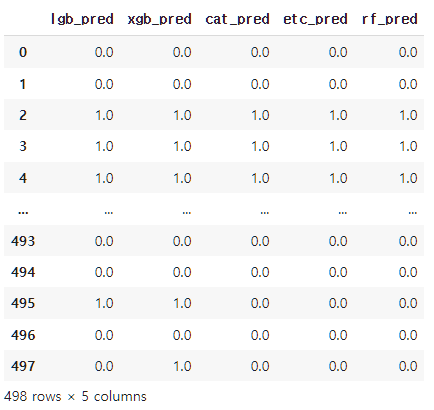
모든 모델에 대해 Train_pred1~5, Test_pred1~5를 구했으면 예측값을 합쳐 하나의 Stacking Data Set을 만듭니다.
temp1 = pd.DataFrame(lgb_train.T, columns = ['lgb_pred'])
temp2 = pd.DataFrame(xgb_train.T, columns = ['xgb_pred'])
temp3 = pd.DataFrame(cat_train.T, columns = ['cat_pred'])
temp4 = pd.DataFrame(etc_train.T, columns = ['etc_pred'])
temp5 = pd.DataFrame(rf_train.T, columns = ['rf_pred'])
stk_train = pd.concat([temp1, temp2, temp3, temp4, temp5], axis = 1)
stk_train
temp1 = pd.DataFrame(lgb_test.T, columns = ['lgb_pred'])
temp2 = pd.DataFrame(xgb_test.T, columns = ['xgb_pred'])
temp3 = pd.DataFrame(cat_test.T, columns = ['cat_pred'])
temp4 = pd.DataFrame(etc_test.T, columns = ['etc_pred'])
temp5 = pd.DataFrame(rf_test.T, columns = ['rf_pred'])
stk_test = pd.concat([temp1, temp2, temp3, temp4, temp5], axis = 1)
stk_test
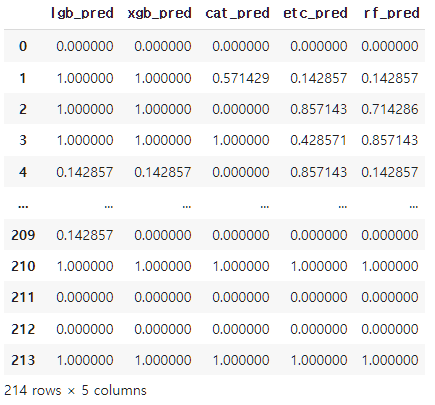
Stacking Model은 Stage 1에서 가장 성능이 좋았던 RandomForest로 결정했습니다. 그러나 꼭 그렇다고 해서 다른 모델을 사용하지 않아야 되는 것은 아닙니다. 저는 편의상 RandomForest를 사용했습니다. 또한 Stage 2에서도 교차검증을 이용했습니다.
# 2-6. stacking
n_fold = 7
cv = StratifiedKFold(n_splits = n_fold, shuffle = True, random_state = 39)
stk_train2 = np.zeros((stk_train.shape[0]))
stk_test2 = np.zeros((stk_test.shape[0]))
print(stk_train2.shape)
for i, (i_trn, i_val) in enumerate(cv.split(stk_train, y_train), 1):
print(f'training model for CV #{i}')
stk_model = RandomForestClassifier(random_state = 39, verbose = False)
stk_model.fit(stk_train.loc[i_trn, :], y_train[i_trn])
stk_train2[i_val] = stk_model.predict(stk_train.loc[i_val, :])
stk_test2 += stk_model.predict(stk_test) / n_fold
stk_train['final_pred'] = stk_train2
stk_train
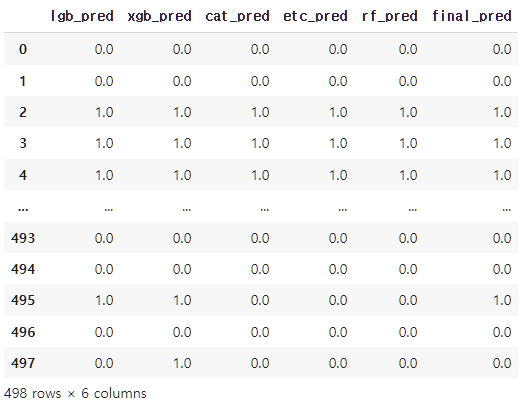
stk_test2의 경우 평균치로 계산됐기 때문에 기준치인 Threshold를 0.5로 두어 0과 1로 다시 분류작업을 진행합니다.
stk_test['final_pred'] = 0
for i in range(stk_test.shape[0]) :
if stk_test2[i] >= 0.5 :
stk_test.loc[i, 'final_pred'] = 1
stk_test
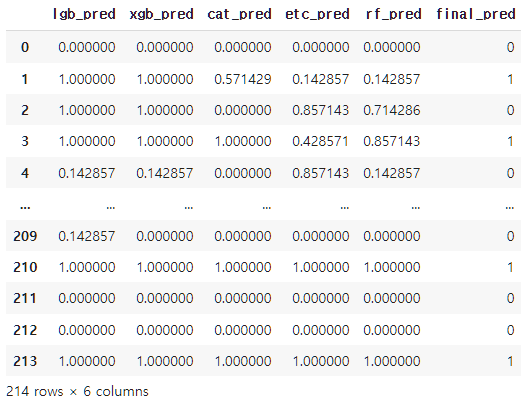
결과적으로 Test Data에 대한 성능은 80.84%가 나왔습니다. RandomForest 단일모델과 동률로 가장 높게 나왔으며, Train Data에도 과대적합되지 않은 안정적인 성능을 보이는 것을 볼 수 있습니다.
print(accuracy_score(y_train, stk_train['final_pred']))
print(accuracy_score(y_test, stk_test['final_pred']))
--------------------------------------------------------------------------------------------------------------------------------
0.8232931726907631
0.8084112149532711
| Model | Accuracy Score(Train) | Accuracy Score(Test) |
|---|---|---|
| 1. LightGBM | 95.38% | 78.97% |
| 2. XgBoost | 97.99% | 79.91% |
| 3. CatBoost | 90.96% | 80.37% |
| 4. ExtraTrees | 98.80% | 78.04% |
| 5. RandomForest | 98.80% | 80.84% |
| 6. Stacking Ensemble | 82.33% | 80.84% |
(3) Blending Ensemble
Blending Ensemble의 경우, Train Data를 다시 PartTrain Data와 Validation Data로 나눠야 합니다.
X_partrain, X_val, y_partrain, y_val = train_test_split(X_train, y_train, test_size = 0.3, random_state = 39, stratify = y_train)
print(X_train.shape, y_train.shape)
print(X_partrain.shape, y_partrain.shape)
print(X_val.shape, y_val.shape)
print(X_test.shape, y_test.shape)
--------------------------------------------------------------------------------------------------------------------------------
(498, 10) (498,)
(348, 10) (348,)
(150, 10) (150,)
(214, 10) (214,)
STAGE 1
마찬가지로 초모수 최적화 작업은 생략하였고 각 모델에 대해 Val_pred와 Test_pred를 추출합니다.
# 3-1. lightgbm blending
lgb_model = LGBMClassifier(random_state = 39)
lgb_model.fit(X_partrain, y_partrain)
lgb_val_pred = lgb_model.predict(X_val)
lgb_test_pred = lgb_model.predict(X_test)
# 3-2. xgboost blending
xgb_model = XGBClassifier(random_state = 39)
xgb_model.fit(X_partrain, y_partrain)
xgb_val_pred = xgb_model.predict(X_val)
xgb_test_pred = xgb_model.predict(X_test)
# 3-3. catboost blending
cat_model = CatBoostClassifier(random_state = 39, verbose = False)
cat_model.fit(X_partrain, y_partrain)
cat_val_pred = cat_model.predict(X_val)
cat_test_pred = cat_model.predict(X_test)
# 3-4. extratrees blending
etc_model = ExtraTreesClassifier(random_state = 39)
etc_model.fit(X_partrain, y_partrain)
etc_val_pred = etc_model.predict(X_val)
etc_test_pred = etc_model.predict(X_test)
# 3-5. randomforest blending
rf_model = RandomForestClassifier(random_state = 39)
rf_model.fit(X_partrain, y_partrain)
rf_val_pred = rf_model.predict(X_val)
rf_test_pred = rf_model.predict(X_test)
STAGE 2
모든 모델에 대해 Train_pred1~5, Test_pred1~5를 구했으면 예측값을 기존 데이터셋인 Validation Data와 Test Data에 각각 추가합니다.
X_val.reset_index(inplace = True, drop = True)
X_test.reset_index(inplace = True, drop = True)
temp1 = pd.DataFrame(lgb_val_pred.T, columns = ['lgb_pred'])
temp2 = pd.DataFrame(xgb_val_pred.T, columns = ['xgb_pred'])
temp3 = pd.DataFrame(cat_val_pred.T, columns = ['cat_pred'])
temp4 = pd.DataFrame(etc_val_pred.T, columns = ['etc_pred'])
temp5 = pd.DataFrame(rf_val_pred.T, columns = ['rf_pred'])
bld_train = pd.concat([X_val, temp1, temp2, temp3, temp4, temp5], axis = 1)
bld_train
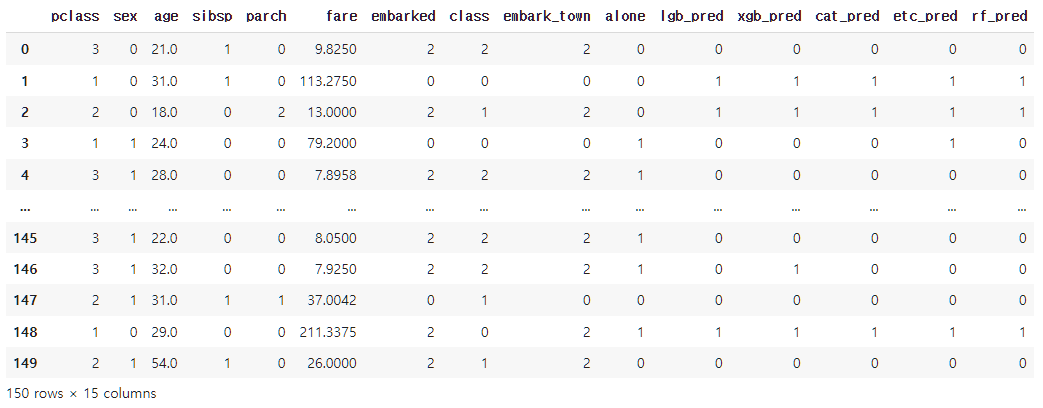
temp1 = pd.DataFrame(lgb_test_pred.T, columns = ['lgb_pred'])
temp2 = pd.DataFrame(xgb_test_pred.T, columns = ['xgb_pred'])
temp3 = pd.DataFrame(cat_test_pred.T, columns = ['cat_pred'])
temp4 = pd.DataFrame(etc_test_pred.T, columns = ['etc_pred'])
temp5 = pd.DataFrame(rf_test_pred.T, columns = ['rf_pred'])
bld_test = pd.concat([X_test, temp1, temp2, temp3, temp4, temp5], axis = 1)
bld_test
Stacking Ensemble과 마찬가지로 Blending Ensemble도 RandomForest를 이용했습니다.
rf_model2 = RandomForestClassifier(random_state = 39)
rf_model2.fit(bld_train, y_val)
rf_val_pred2 = rf_model2.predict(bld_train)
rf_test_pred2 = rf_model2.predict(bld_test)
print(accuracy_score(y_val, rf_val_pred2))
print(accuracy_score(y_test, rf_test_pred2))
--------------------------------------------------------------------------------------------------------------------------------
1.0
0.7570093457943925
결과적으로, Blending Ensemble은 7개의 모델 중 가장 큰 과대적합 경향성을 보이며, 성능도 가장 좋지 않았습니다. 사실 개인적으로 Blending Ensemble은 권해드리진 않습니다. 보시다시피 과대적합이 나타날 가능성이 매우 크기 때문입니다. 만약, 공모전이나 프로젝트를 수행한다면 다소 알고리즘이 복잡하지만 성능이 조금 더 올라갈 수 있는 Stacking Ensemble을 추천드립니다.
| Accuracy Score(Train) | Accuracy Score(Test) | |
|---|---|---|
| 1. LightGBM | 95.38% | 78.97% |
| 2. XgBoost | 97.99% | 79.91% |
| 3. CatBoost | 90.96% | 80.37% |
| 4. ExtraTrees | 98.80% | 78.04% |
| 5. RandomForest | 98.80% | 80.84% |
| 6. Stacking Ensemble | 82.33% | 80.84% |
| 7. Blending Ensemble | 100.00% | 75.70% |
Reference

댓글남기기