[Modeling] NGBoost
안녕하세요. 내일부터 해외 출장이 있는데 가기 전에 최근에 알게 된 Boosting 기법에 대해 포스팅하려고 합니다. 바로 NGBoost 입니다! 이미 많이 알려진 Boosting 기법으로 GBM, XGBoost, LightGBM, CatBoost 등이 있죠. 저도 머신러닝을 할 때 이들을 주로 많이 이용합니다. 이 모델은 최근에 Dacon 대회에 참여해서 처음 알게 되었습니다. 상위권 사람들이 이를 이용해서 좋은 성과를 내는 것을 보고 기존의 Boosting과 어떻게 다른지 궁금해서 공부하게 되었습니다!
정의
NGBoost(Natural Gradient Boost)는 Natural gradient라는 방식을 활용해서 실제값에 가깝게 값을 예측해주는 Boosting 기법입니다. NGBoost가 가지고 있는 가장 큰 특징은 종속변수 Y의 개별 데이터에 대한 예측을 진행하는 다른 기법과 달리 확률적 예측으로 데이터에 대한 분포 반환을 목표로 한다는 점입니다. 예를 들어, 특정 지역의 부동산 데이터 분석을 통해 주택 가격을 예측하려고 합니다. 따라서 Boosting 모델링을 진행하여 특정 데이터에 대해 주택 가격이 25억임을 예측했습니다. 하지만 이 25억이라는 가격이 실제로 얼마의 신뢰성을 가지는지 알지 못합니다. NGBoost는 이러한 예측의 불확실성까지 알려줍니다. 즉, 주택 가격이 25억일 확률이 대략적으로 70% 정도 된다!는 결론을 만들어 줍니다.
이렇듯 단순히 점 추정치를 맞추는데만 초점을 두지 않고, 각각의 데이터 X 지점에서의 평균과 분산을 추정하여 전반적인 데이터에 대한 확률 분포를 찾고자 하는 기법입니다. 이러한 특징으로 특히 제조, 의학과 같은 분야의 Survival Analysis로도 활용성이 높은 기법이라고 할 수 있습니다. 단점은 XGBoost와 LightGBM보다는 상대적으로 Fitting 시간이 걸린다는 점이 있습니다.
이 기법에 대한 내용은 아래 Reference의 논문에 상세히 나와있는데 Natural Gradient, Divergence Metric, Manifold 등 각종 알고리즘과 수식을 이해하기가 다소 까다롭고 내용이 깁니다. 따라서 그 원리에 대한 내용은 우선 생략하고 실제 데이터를 활용하여 직접 진행을 해보겠습니다.
실습
사용한 데이터는 Boston Housing 1970 데이터입니다. 아래와 같이 전처리해서 가져오겠습니다.
-
데이터 특징
- Boston Housing 1970 Data : $(506, 17)$
df = pd.read_csv("https://raw.githubusercontent.com/yoonkt200/FastCampusDataset/master/BostonHousing2.csv")
df['BOSTON'] = 0
for i in range(df.shape[0]) :
if 'Boston' in df.loc[i, 'TOWN'] :
df.loc[i, 'BOSTON'] = 1
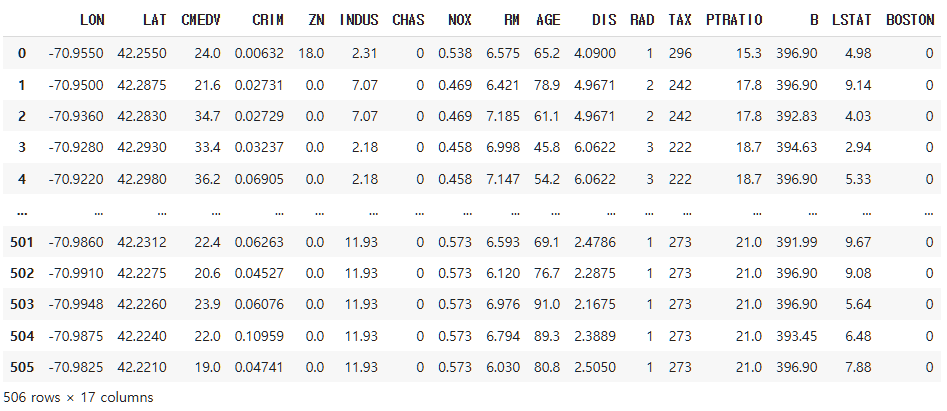
df2 = df.drop(['TOWN'], axis = 1)
df2

X = df2.drop(['CMEDV'], axis = 1)
y = df2['CMEDV']
print(X.shape)
print(y.shape)
--------------------------------------------------------------------------------------------------------------------------------
(506, 16)
(506,)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 39)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
--------------------------------------------------------------------------------------------------------------------------------
(354, 16)
(152, 16)
(354,)
(152,)
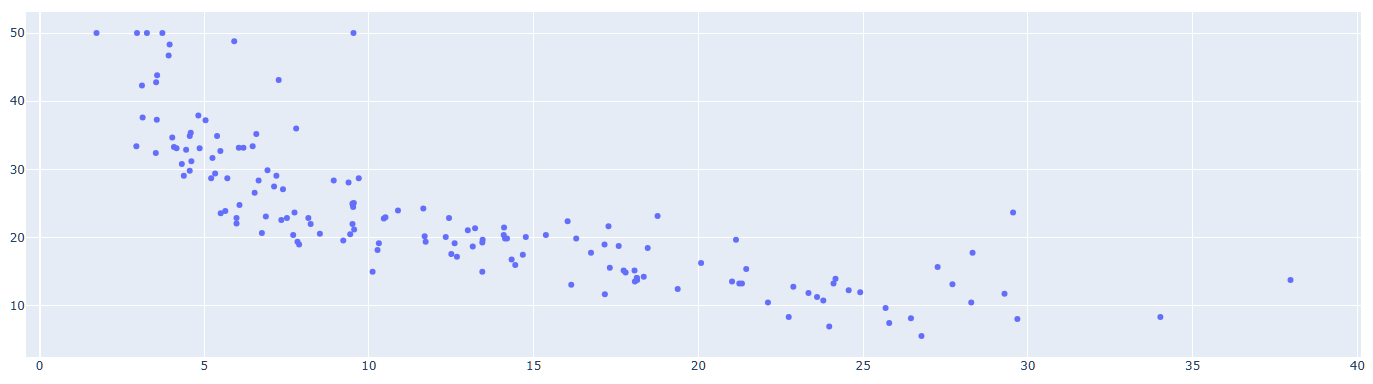
먼저 X_test의 산포도를 보겠습니다. 그래프에서 X는 설명변수 16개 중 종속변수와 가장 상관계수가 높았던 LSTAT로, Y는 종속변수인 CMEDV로 두었습니다.
import plotly.express as px
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Scatter(x = X_test.LSTAT, y = y_test, mode = 'markers', name = 'TRAIN SET'))
fig.show()
이 때, NGBoost 모델을 적합시켜보겠습니다. 그리고 아래와 같이 X_train과 X_test의 predict 값에 대한 MAPE를 구했습니다.
# MAPE를 구하는 함수 만들기 1
def percentage_error(actual, predicted):
res = np.zeros(actual.shape)
for j in range(actual.shape[0]):
if actual[j] != 0:
res[j] = (actual[j] - predicted[j]) / actual[j]
else:
res[j] = predicted[j] / np.mean(actual)
return res
# MAPE를 구하는 함수 만들기 2
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs(percentage_error(np.asarray(y_true), np.asarray(y_pred)))) * 100
X_train.reset_index(inplace = True, drop = True)
y_train.reset_index(inplace = True, drop = True)
X_test.reset_index(inplace = True, drop = True)
y_test.reset_index(inplace = True, drop = True)
# NGBOOST 모델 적합
ngb_norm = NGBRegressor().fit(X_train, y_train)
train_pred = ngb_norm.pred_dist(X_train)
test_pred = ngb_norm.pred_dist(X_test)
# MAPE 값 도출
MAPE_train = mean_absolute_percentage_error(y_train, train_pred.loc)
MAPE_test = mean_absolute_percentage_error(y_test, test_pred.loc)
print('MAPE_train', MAPE_train)
print('MAPE_test', MAPE_test)
--------------------------------------------------------------------------------------------------------------------------------
MAPE_train 4.886114170521553
MAPE_test 13.288382281584799
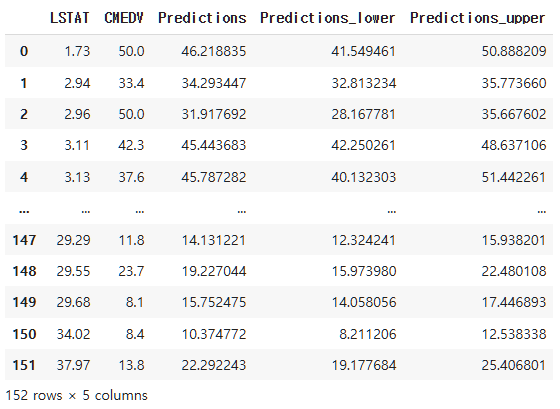
이제 TEST 데이터의 Predict 값에 대해 95% Interval를 구해보겠습니다. 즉, 각각에 예측값에 대해 어느 정도까지 신뢰성이 있는지 그래프로 그려볼 수 있습니다. 함수는 dist.interval(0.95)를 이용합니다.
predictions = pd.DataFrame(test_pred.loc, columns=['Predictions'])
predictions_upper = pd.DataFrame(test_pred.dist.interval(0.95)[1], columns = ['Predictions_upper'])
predictions_lower = pd.DataFrame(test_pred.dist.interval(0.95)[0], columns = ['Predictions_lower'])
df_figure = pd.concat([X_test['LSTAT'], y_test, predictions, predictions_lower, predictions_upper], axis = 1)
df_figure2 = df_figure.sort_values(['LSTAT'])
df_figure2.reset_index(inplace = True, drop = True)
df_figure2
fig, ax = plt.subplots(figsize = (22, 5))
plt.plot(df_figure2.LSTAT, df_figure2.Predictions, label = 'Predictions', color = 'b', lw = 2)
plt.fill_between(df_figure2.LSTAT, df_figure2.Predictions_lower, df_figure2.Predictions_upper, label = '95% Prediction Interval', color = 'gray', alpha = 0.5)
plt.scatter(df_figure2.LSTAT, df_figure2.CMEDV, label = 'Actual', color = 'g', lw = 3)
ax.legend(fontsize = 14)
plt.show()
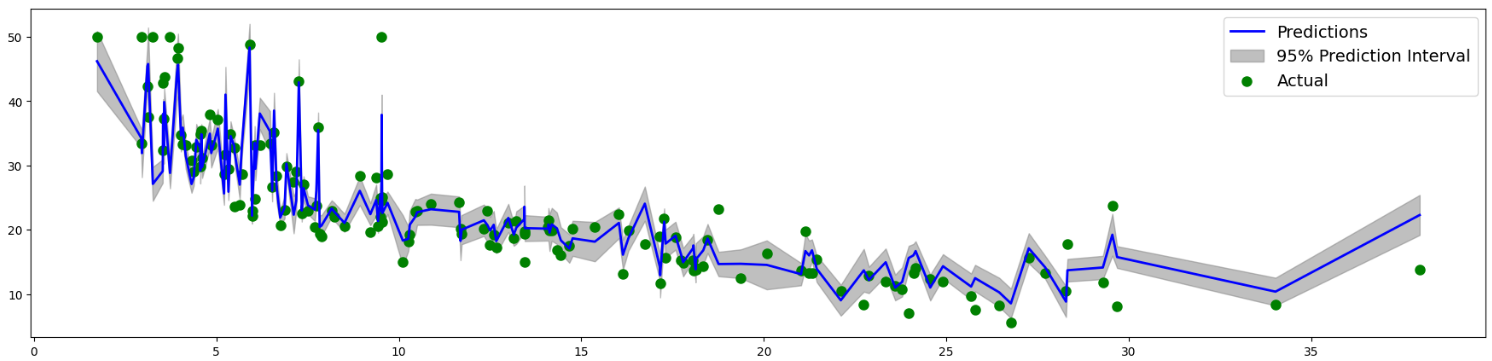
이와 같이 NGBoost를 통해 예측값에 대한 신뢰성을 판단할 수 있으며, 일반적으로 유사한 초모수에 대해서는 LightGBM보다 NGBoost가 속도는 느리나, 조금 더 정확하다는 사실이 알려져 있습니다.
Reference
- AI-stoster
- 귀퉁이 서재
- NGBoost: Natural Gradient Boosting for Probabilistic Prediction
- kaggle
- DMQA
- NgBoost User Guide

댓글남기기